

Unlocking Data Insights: The Comprehensive Guide to Exploratory Data Analysis (EDA) in Data Science
In the vast landscape of data science, Exploratory Data Analysis (EDA) stands as a pivotal process that sets the stage for deriving meaningful insights, identifying patterns, and making informed decisions based on data. This comprehensive guide will answer question such as what is EDA, what is Exploratory Data Analysis (EDA), what is EDA in Data Science, why it’s crucial, data cleaning, validity, imputation techniques, data analysis and visualization, transformations, and the emerging trend of automated EDA (Auto EDA).
What is Exploratory Data Analysis (EDA)?
Exploratory Data Analysis (EDA) is a data analysis approach aimed at summarizing the main characteristics of a dataset, often using graphical and statistical methods. It involves examining and understanding the underlying structure, patterns, distributions, relationships, and anomalies within the data before proceeding to more complex analysis. EDA helps data scientists gain a preliminary understanding of the data and formulate hypotheses for further investigation
Why Exploratory Data Analysis (EDA) is Necessary
EDA serves multiple crucial purposes in data science:
- Data Understanding: EDA helps analysts understand the structure, content, and quality of datasets, providing a foundation for further analysis.
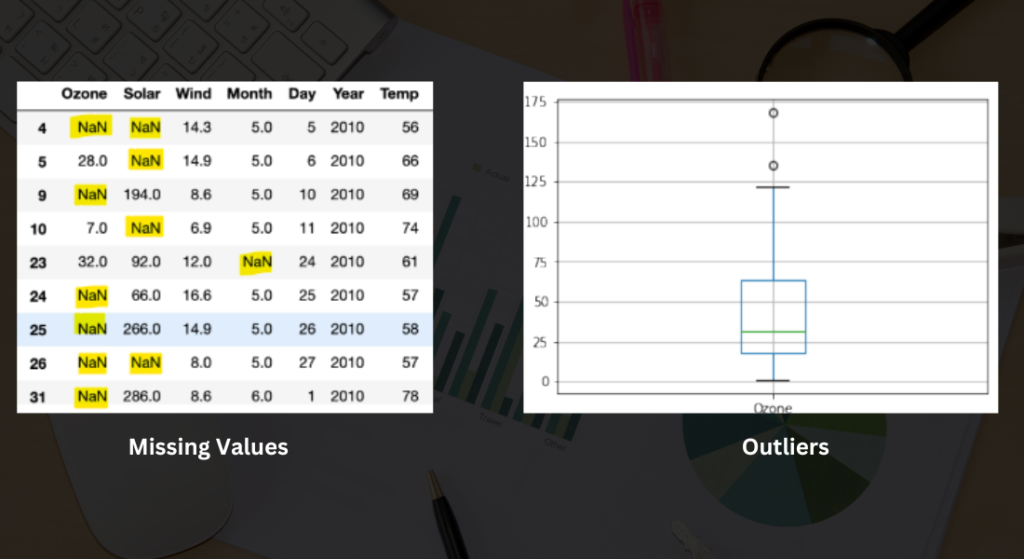
- Data Cleaning: EDA identifies missing values, outliers, and inconsistencies in data, guiding data cleaning processes to ensure data integrity and accuracy.
- Data Validity: EDA assesses the validity and relevance of data, ensuring that it aligns with the intended objectives and analysis requirements.
- Imputation Techniques: EDA guides the selection and application of imputation techniques for handling missing data, such as mean imputation, median imputation, or predictive imputation.
- Data Analysis and Visualization: EDA involves statistical analysis and data visualization techniques to uncover patterns, trends, correlations, and outliers in data, facilitating deeper insights and decision-making.
- Transformations: EDA may involve data transformations, such as log transformations or scaling, to normalize data distributions and improve analysis accuracy.
- Auto EDA: With the advent of automated EDA tools and libraries, such as pandas-profiling, DataExplorer, and AutoViz, EDA processes can be streamlined and accelerated, allowing for rapid insights generation.
Data Cleaning
One of the primary objectives of EDA is data cleaning, which involves identifying and addressing issues such as missing values, duplicate records, inconsistencies, and outliers. Techniques used in data cleaning during EDA include:
- Handling Missing Values: Imputation techniques like mean imputation, median imputation, mode imputation, or advanced imputation methods based on predictive models.
- Outlier Detection: Statistical methods such as z-score analysis, IQR (Interquartile Range) method, or visualization-based outlier detection techniques.
- Duplicate Record Identification: Identifying and removing duplicate records based on unique identifiers or key fields in the dataset.
- Inconsistent Data Handling: Addressing inconsistencies in data formats, units of measurement, or data entry errors through validation and standardization.
Data Analysis and Visualization
EDA encompasses a wide range of data analysis and visualization techniques to uncover insights and patterns:
- Descriptive Statistics: Summary statistics such as mean, median, mode, standard deviation, variance, and percentiles are used to describe data distributions.
- Data Visualization: Visual representations such as histograms, box plots, scatter plots, heatmaps, and correlation matrices are created to visualize data patterns, trends, and relationships.
- Correlation Analysis: Correlation analysis is performed to identify relationships and dependencies between variables, helping in feature selection and predictive modelling.

Transformations
Data transformations are applied during EDA to pre-process and prepare data for analysis:
- Log Transformations: Logarithmic transformations are used to handle skewed data distributions and improve model performance.
- Scaling and Normalization: Variables are scaled or normalized to a standard range to ensure consistency and comparability across features.
- Feature Engineering: New features and variables are created based on existing data to enhance predictive power and model performance.
Auto EDA
Emerging technologies like Auto EDA offer automated solutions for conducting EDA:
- Automated Data Cleaning: Algorithms and machine learning techniques automatically identify and address data quality issues, improving data integrity and analysis outcomes.
- Automated Feature Engineering: Automated feature engineering techniques generate new features and variables based on data patterns and relationships, enhancing predictive modelling capabilities.
- Automated Visualization: Interactive dashboards and visualizations are automatically generated to explore data insights and trends seamlessly.
Conclusion
Exploratory Data Analysis (EDA) plays a pivotal role in the data science workflow, enabling data scientists to gain insights, assess data quality, generate hypotheses, and prepare data for further analysis. By leveraging EDA techniques such as data cleaning, analysis, visualization, transformations, and emerging trends like Auto EDA, data scientists can unlock the full potential of data and drive informed decision-making processes.